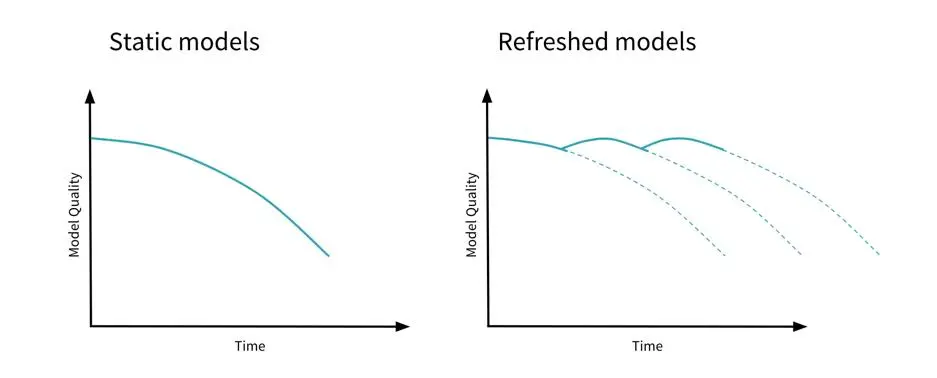
Model drift is a common issue in machine learning where the performance of a model degrades over time due to changes in the input data distribution.
Some key terms and concepts related to model drift include:
Data drift: a type of model drift where the distribution of the input data changes over time, leading to inaccurate and unreliable predictions by the model
Concept drift: a type of model drift where the relationship between the input features and the output labels changes over time, leading to inaccurate and unreliable predictions by the model
Covariate shift: a type of data drift where the distribution of the input features changes over time, leading to inaccurate and unreliable predictions by the model
Prior probability shift: a type of concept drift where the prior probabilities of the output labels change over time, leading to inaccurate and unreliable predictions by the model
Real-time monitoring: the process of monitoring the performance of the model in real-time and detecting when model drift occurs
Re-training: the process of updating the model with new data to account for changes in the input data distribution and improve its performance
Retraining schedule: a predefined schedule for re-training the model on new data to account for changes in the input data distribution
Validation data: a separate dataset used to evaluate the performance of the model and detect when model drift occurs.
Model drift is a common challenge in machine learning, but can be addressed by monitoring for changes in the input data distribution and using appropriate re-training techniques. By detecting and addressing model drift, developers can ensure that their models remain accurate and reliable over time in real-world use cases. Here are some ways developers can effectively address model drift and ensure that their models remain accurate and reliable over time in real-world use cases:
| Strategy | Description |
|---|---|
| Real-time monitoring | Monitor the model’s performance in real-time and detect when model drift occurs. |
| Retraining | Retrain the model with new data to account for changes in the input data distribution and improve its performance. |
| Retraining schedule | Establish a predefined schedule for re-training the model on new data to account for changes in the input data distribution. |
| Data augmentation | Augment the existing dataset with additional data to improve the model’s ability to generalize to new data. |
| Ensemble models | Use ensemble models that combine multiple models to improve the accuracy and reliability of the predictions. |
| Active learning | Incorporate active learning techniques to select the most informative data points for model training, thereby reducing the impact of data drift. |
| Data quality checks | Perform regular checks on the data to ensure that it is accurate, consistent, and representative of the real-world data. |
| Validation data | Set aside a separate dataset for validation purposes and use it to evaluate the performance of the model and detect when model drift occurs. |
| Concept drift detection | Use algorithms to detect changes in the input data distribution and adjust the model’s parameters accordingly. |
