Apache Spark is an emerging de facto platform and trade language for big data analytics. It has a high computing power and a set of libraries for parallel big data processing on compute clusters. It complements the Hadoop paradigm.
Spark enables data scientists and developers to work and process a lot of data (Big data) in a manner that is more conducive. This is possible because Spark processes its workload in a completely distributed manner without the need for repeated writing of the results to the disk. It is also very fast in processing because it stores data in memory (RAM) rather than on disk.
Spark also provides a unified runtime, which is responsible for connecting to different big data storage sources, such as HBase, Cassandra, HDFS and S3 buckets in AWS.
It also provides high-level libraries, which help in different big data computing tasks, making development faster.
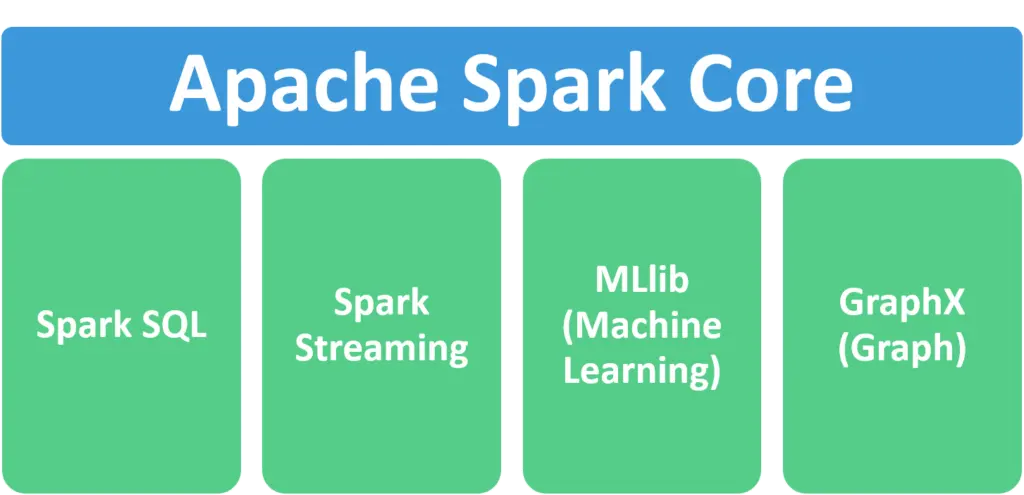
These libraries make part of the Spark ecosystem:
Spark SQL - It is used to support accessing data using the standard SQL queries and HiveQL, a SQL-like query language that Hive uses. Spark SQL uses a programming abstraction called DataFrame.
Spark Streaming - When it comes to real-time analytics and processing real-time Big data, spark streaming is the holy grail. It enables spark to ingest live data streams and provides real-time intelligence at a very low latency of a few seconds.
MLlib - When it comes to machine learning, Apache spark has ML lib which is built on top of spark and it supports building machine learning pipelines. It also contains in-built algorithms ranging from classification, regression, and clustering.
Graph X - Graph analysis is much more common in our lives than we think, we even use it every day, for example when finding the shortest route to your destination, it uses the graph-processing algorithm.
Graph X is the Spark API for graph and graphical computations, and graph processing. It provides a wrapper around an RDD called a resilient distributed property graph.
If you want:
- A fast and general-purpose engine for large-scale processing
- An engine that supports more types of computations
- To perform ETL or SQL batch jobs with large data sets
- To process streaming, real-time data from sensors, IoT, or financial systems, especially in combination with static data
- To perform complex graph analysis.
- To perform heavy machine-learning tasks
Then, Apache Spark will be an appropriate tool to use.
